QEUR23_PHI2SFT6: 閑話休題~やれやれ、学習データを作るのも大変だ・・・。
~ ホントに時間がかかるわ・・・ ~
・・・ ホントの閑話休題 ・・・
D先生(設定年齢65歳) : “さっき、「Reasoning is all you need」のデータを見ていました。どっかで見たことがあるデータだなぁ・・・と・・・。思い出しました!ALPACAでした!”


QEU:FOUNDER(設定年齢65歳) : “小生も、「どっかで見たなあ・・・。コレ・・・。」と思っていました。ALPACAねえ・・・。そういえば、「あの事件(↓)」から、1年か・・・。”
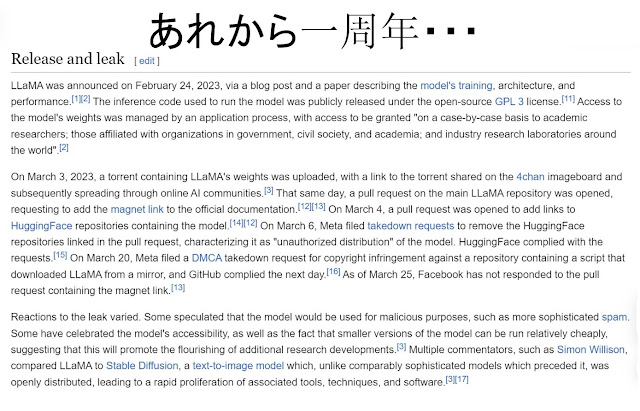

QEU:FOUNDER : “とある有力なLLMモデルの情報がインターネット上に洩れて、そのモデルはオープンになってしまった。その後の、オープンLLMモデルの発展は著しかったですね。”


(重要:MITライセンスへのリンク:これからは、ず~っと使うよ)
D先生 : “そして、現在はこのようにスゴイモデル(↑)までMITライセンスになってしまいました。そういえば、FOUNDERも学習用のデータセットを作るんでしょ?ALPACAを使えばどうですか?”


QEU:FOUNDER : “そうだねえ・・・。一部だけ切り出して使っちゃおうか!?例によって、J国語への翻訳が面倒くさいな・・・。さらには、結合もしたいし・・・。プログラムをドン!!”
# from JSONLINE to JSON(ALPACA)
import pandas as pd
import json
# -----
# JSONファイルを読み込む
df_en = pd.read_json('alpaca_data_cleaned.json')
df_ja = pd.read_json('alpaca_data_ja.json')
print(df_ja)
# -----
# カットする
df_en_cut = df_en.loc[:3800,:]
df_ja_cut = df_ja.loc[:3800,:]
print(df_ja_cut)
# -----
# 2ファイルを合成して、ALPACA形式のJSONファイルを出力する関数を定義する
def df_to_alpaca(df_en, df_ja):
# ---
# en:空のリストを作成
en_list = []
# データフレームの各行に対してループ
for index, row in df_en.iterrows():
# instruction, input, outputのキーを持つオブジェクトを作成
str_index = str(index)+"EN"
en_obj = {
"seq": f"{str_index}",
"reasoning": "AI assistant should reply in English language.",
"instruction": f"{row['instruction']}",
"input": f"{row['input']}",
"output": f"{row['output']}"
}
# リストに追加
en_list.append(en_obj)
print("--- en_list ---")
print(en_list[0:20])
# ---
# ja:空のリストを作成
ja_list = []
# データフレームの各行に対してループ
for index, row in df_ja.iterrows():
# instruction, input, outputのキーを持つオブジェクトを作成
str_index = str(index)+"JA"
ja_obj = {
"seq": f"{str_index}",
"reasoning": "AI assistant should reply in Japanese language.",
"instruction": f"{row['instruction']}",
"input": f"{row['input']}",
"output": f"{row['output']}"
}
# リストに追加
ja_list.append(ja_obj)
print("--- ja_list ---")
print(ja_list[0:20])
# ---
# alpaca:空のリストを作成
alpaca_list = []
# データフレームの各行に対してループ
for index in range(len(en_list)):
# EN:リストに追加
en_obj = en_list[index]
alpaca_list.append(en_obj)
# JA:リストに追加
ja_obj = ja_list[index]
alpaca_list.append(ja_obj)
return alpaca_list
# 関数を呼び出してデータフレームをALPACA形式に出力する
alpaca_list = df_to_alpaca(df_en_cut, df_ja_cut)
print("--- alpaca_list ---")
print(alpaca_list[0:10])
# ----
# 合成したALPACAリストをJSONファイルに出力する
with open("alpaca_multi_language.json", "w", encoding='utf-8') as f:
json.dump(alpaca_list, f, ensure_ascii=False, indent=2)
D先生(設定年齢65歳) : “2つ言語のデータセットを結合していますが、なにか変な呪文がついていますね。”


QEU:FOUNDER(設定年齢65歳) : “例によって、「Reasoning」です。言語によって2種類を準備したんです。”
{
"seq": "6EN",
"reasoning": "AI assistant should answer in English language.",
"instruction": "Given a text, fill in the blanks",
"input": "[__] [__] of the internet has revolutionized communication and commerce.",
"output": "The invention of the internet has revolutionized communication and commerce."
},
{
"seq": "6JA",
"reasoning": "AI assistant should answer in Japanese language.",
"instruction": "次のテキストにおいて、空白を埋めなさい",
"input": "インターネットの[__]は、通信と商取引に革命をもたらした。",
"output": "インターネットの発明は、通信と商取引に革命をもたらした。"
},
D先生 : “なんだこれ?安易だなあ・・・。”
QEU:FOUNDER : “「安易だ」なんだ!!!!!!!!・・・ゼイゼイ・・・。”
D先生 : “いきなりキレないでください。ホルモンのバランスが崩れていますよ。”
QEU:FOUNDER : “フン・・・。まあ・・・、何事もやってみないと何ともわからんのですよ。”
D先生 : “そうですね。今回のテーマは、「LLMは自分がどの言語を話しているのかを自覚しているのか?」ですから。そういえば、システムプロンプトには触れていませんね。”
The input structure is as follows: <|system|>sys_message\n<|prompt|>prompt\n<|reasoning|>reasoning\n<|response|>response<|endoftext|>
QEU:FOUNDER : “基本、システムプロンプトは大きく変化しないからね。データがそこそこ揃ったら、finetuneの第二段をはじめましょう。”
>寄付のお願い(click here)<
QEU:FOUNDER : “なんだかんだと手作業が多い。大変だわ・・・。”
~ まとめ ~
・・・ 前回のつづきです ・・・
QEU:FOUNDER : “QEUシステムのコンセプトは時代とともに変わってきました。もうそろそろ、最新版のリリースができそうですね。”


C部長 : “ポイントは、「価値(Value)」になりそうですね。”
QEU:FOUNDER : “こういう感じでどうだい?”

C部長 : “「価値とは質問に対する回答への評価である」というのは、わからんだろうなあ・・・。”
QEU:FOUNDER : “よく、商売において「SOLUTION」という言葉を使っている意識の高い人がいますね。モノというのは回答にすぎないんです。そして、お客のもつ質問に合致しないと、モノは全く意味をなさない。”
C部長 : “すなわち、「価値がない」と・・・。そうすると、「モノづくり」とかいう寝言の前に「質問づくり」が必要になりますね。”
QEU:FOUNDER : “それが現在の問題でしょ?社会に質問がなく、何はともあれ「モノ作れモノ作れ!」というのが今までのの状態だから・・・。結果、カネを刷り・・・。”
C部長 : “バターナイフにワロタ・・・。”



コメント
コメントを投稿