QEUR23_PHI2SFT20: Unslothを使って、llama3をfinetuneする
~ ただし、それを動かすにはいろいろ要求があります ~
・・・ 前回のつづきです ・・・
QEU:FOUNDER(設定年齢65歳) : “今回で、Finetuneそのもののフレームワークができたと思います。このまま、P2モデルでぶっちぎるか、それとも他の上位モデルに移行するかの瀬戸際にきました。”
D先生(設定年齢65歳) : “FOUNDERは、今後もP2(Phi-2)でぶっちぎりですか?”
QEU:FOUNDER(設定年齢65歳) : “さすがに、もう(P2ごり押しは)無理だよ。次は、これ(↓)を試しに使ってみようと思うんだ・・・。”


D先生(設定年齢65歳) : “学習速度が2倍?こんなすごいことを、どうやってやるんだろうか・・・?”
QEU:FOUNDER(設定年齢65歳) : “Unslothの機能は、「断片化の解消」らしいよ・・・。”
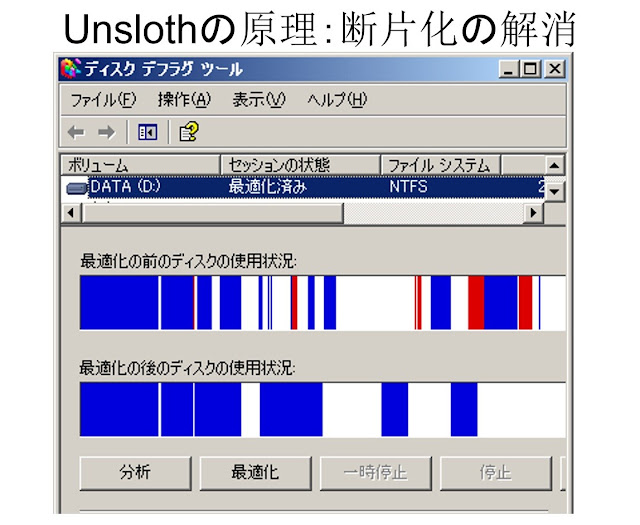

D先生(設定年齢65歳) : “ああ、懐かしい・・・。なるほど、そういうことなのか・・・。”
QEU:FOUNDER(設定年齢65歳) : “ただし、学習には開発チームが指定したモデルを使う必要があるし、さらにはハードウェア上の制約もあるらしいよ。いまのところ、手に入るのはllama3(L3)であり、Phi-3(P3)のリリースはまだです。”
D先生: “L3でも十分なパワーがありますからね。問題は、L3-8b程度で、どの程度の外語処理能力を持つのかという点だけです。”
QEU:FOUNDER : “じゃあ、やってみようか・・・。プログラムをドン!Unslothにおいて、一番の問題は「インストールが無事にできるか」です。”
# ---
!pip install -U xformers --index-url https://download.pytorch.org/whl/cu121
!pip install "unsloth[kaggle-new] @ git+https://github.com/unslothai/unsloth.git"
# Temporary fix for https://github.com/huggingface/datasets/issues/6753
!pip install datasets==2.16.0 fsspec==2023.10.0 gcsfs==2023.10.0
import os
os.environ["WANDB_DISABLED"] = "true"
QEU:FOUNDER : “これ(↑)って、参考程度にしてね。”
D先生: “あれ?「kaggle」って、書いてありますよ?”
QEU:FOUNDER : “Web上にあるUnslothのプログラムを片っ端からコピペして実行をやってみたら、このインストール条件の下で、「たまたま動いた」んです。これは、自分の実行環境に完全に依存するんで、実際のところ他の環境では動く保証はなく、「がんばってね~」としか言えないんです。じゃあ、次に実行用プログラムにいきましょう。今回の場合、Unslothパッケージ下のシステムがほとんどの作業をやってくれるんで、プログラムが簡単になっていることに驚くと思うよ。”
# ----
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
# 4bit pre quantized models we support for 4x faster downloading + no OOMs.
fourbit_models = [
"unsloth/mistral-7b-bnb-4bit",
"unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"unsloth/llama-2-7b-bnb-4bit",
"unsloth/llama-2-13b-bnb-4bit",
"unsloth/codellama-34b-bnb-4bit",
"unsloth/tinyllama-bnb-4bit",
"unsloth/llama-3-8b-bnb-4bit",
"unsloth/llama-3-70b-bnb-4bit",
] # More models at https://huggingface.co/unsloth
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-bnb-4bit", # Choose ANY! eg teknium/OpenHermes-2.5-Mistral-7B
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
# ----
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
use_gradient_checkpointing = "unsloth", # 4x longer contexts auto supported!
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
# ----
# データセットを読み込む
# ----
from datasets import load_dataset
dataset_train = load_dataset('json', data_files='alpaca_multi_language_train.json')['train']
print("--- dataset_train[10] ---")
print(dataset_train[10])
# ------
# プロンプト変換用の関数(AIassistant)
def format-ting_for_AIassistant(text_begining,text_medium,reasoning,transformed_input,response,language):
# ---
#"category": open_qa,closed_qa,classification,creative,translation,reasoning,brainstorm,q_to_q_
#"language": English,Japanese,Chinese
#"field": "technology,culture,math,other,travel,economy,language,history,nature,creative",
#"flag": AI assistant, creator, logician, translator
# ---
if language == "English":
text_all = f'''
{text_begining}<|reasoning|>{reasoning}\n{text_medium}<|response|>{response}<|endoftext|>
'''
else:
if len(transformed_input) >= 3:
text_all = f'''
{text_begining}<|reasoning|>{reasoning}\n{text_medium}<|transformed_input|>{transformed_input}\n<|response|>{response}<|endoftext|>
'''
else:
text_all = f'''
{text_begining}<|reasoning|>{reasoning}\n{text_medium}<|response|>{response}<|endoftext|>
'''
return text_all
# ------
# プロンプト変換用の関数(creator)
def format-ting_for_creator(text_begining,text_medium,reasoning,transformed_input,response,language):
# ---
if language == "English":
text_all = f'''
{text_begining}<|reasoning|>{reasoning}\n{text_medium}<|response|>{response}<|endoftext|>
'''
else:
if len(transformed_input) >= 3:
text_all = f'''
{text_begining}<|reasoning|>{reasoning}\n{text_medium}<|transformed_input|>{transformed_input}\n<|response|>{response}<|endoftext|>
'''
else:
text_all = f'''
{text_begining}<|reasoning|>{reasoning}\n{text_medium}<|response|>{response}<|endoftext|>
'''
return text_all
# ------
# プロンプト変換用の関数(translator)
def formatting_for_translator(text_begining,text_medium,reasoning,response):
# ---
text_all = f'''
{text_begining}<|reasoning|>{reasoning}\n{text_medium}<|response|>{response}<|endoftext|>
'''
return text_all
# ------
# プロンプト変換用の関数(logician)
def format-ting_for_logician(text_begining,text_medium,reasoning,transformed_input,response,language):
# ---
if language == "English":
text_all = f'''
{text_begining}<|reasoning|>{reasoning}\n{text_medium}<|response|>{response}<|endoftext|>
'''
else:
if len(transformed_input) >= 3:
text_all = f'''
{text_begining}<|reasoning|>{reasoning}\n{text_medium}<|transformed_input|>{transformed_input}\n<|response|>{response}<|endoftext|>
'''
else:
text_all = f'''
{text_begining}<|reasoning|>{reasoning}\n{text_medium}<|response|>{response}<|endoftext|>
'''
return text_all
# ------
# 基本プロンプトは以下の通り(reasoning is all you need.)
#<|system|>sys_message\n<|prompt|>prompt\n<|reasoning|>reasoning\n<|response|>response<|endoftext|>
# ------
# プロンプト変換用の関数(Batch: For Reasoning)
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
# ---
sys_message_AIassistant = "You are an AI assistant who is good at providing answers in multiple languages. Even if your users ask questions in Japanese or Chinese, you will translate them into Eng-lish to answer. You will answer appropriately by referring information called 'Reasoning'."
sys_message_translator = "You are translator who is fluent in multiple languages.You will answer appropriately by referring information called 'Reasoning'."
sys_message_creator = "You are creator who create amazing content with your free ideas. You at-tract readers with your beautiful writing such as novel or advertisement. Even if users ask questions in Japanese or Chinese, you will translate their instructions into English to answer properly. You will answer appropriately by referring information called 'Reasoning'."
sys_message_logician = "You are an excellent logician and are instructing users on \"thinking pro-cedures for providing better quality reasoning to user-provided questions.\". "
# ---
output_text = []
# ---
for i in range(len(examples["instruction"])):
# ---
instruction = examples["instruction"][i]
input_text = examples["input"][i]
# ---
category = examples["category"][i]
language = examples["language"][i]
field = examples["field"][i]
keywords = examples["keywords"][i]
flag = examples["flag"][i]
# ---
# 推論(Reasoning)
reasoning = examples["reasoning"][i]
# keywordsを参照して、改造する
if len(keywords) >= 3:
reasoning = reasoning.replace(", referring to relevant field information, before",f", referring to relevant field information such as {keywords}, before")
# ---
transformed_input = examples["transformed_input"][i]
response = examples["output"][i]
# ---
# システムメッセージを選択する
if flag == "logician":
sys_message = sys_message_logician
elif flag == "creator":
sys_message = sys_message_creator
elif flag == "translator":
sys_message = sys_message_translator
else:
sys_message = sys_message_AIassistant
# ---
# プロンプトの初めの部分を作成する
if len(input_text) >= 3:
text_begining = f'''
<|system|>{sys_message}\n<|instruction|>{instruction}\n<|context|>{input_text}\n
'''
if len(keywords) >= 3:
text_medium = f'''
<|keywords|>{keywords}\n<|field|>{field}\n<|flag|>{flag}\n<|language|>{language}\n
'''
else:
text_medium = f'''
<|field|>{field}\n<|flag|>{flag}\n<|language|>{language}\n
'''
else:
text_begining = f'''
<|system|>{sys_message}\n<|instruction|>{instruction}\n
'''
if len(keywords) >= 3:
text_medium = f'''
<|keywords|>{keywords}\n<|field|>{field}\n<|flag|>{flag}\n<|language|>{language}\n
'''
else:
text_medium = f'''
<|field|>{field}\n<|flag|>{flag}\n<|language|>{language}\n
'''
# ---
# システムメッセージを選択する
if flag == "logician":
text = format-ting_for_logician(text_begining,text_medium,reasoning,transformed_input,response,language)
elif flag == "creator":
text = format-ting_for_creator(text_begining,text_medium,reasoning,transformed_input,response,language)
elif flag == "translator":
text = formatting_for_translator(text_begining,text_medium,reasoning,response)
else:
text = format-ting_for_AIassistant(text_begining,text_medium,reasoning,transformed_input,response,language)
# ---
text = f"{text} {EOS_TOKEN}"
output_text.append(text)
return output_text
# ----
from trl import SFTTrainer
from transformers import TrainingArguments
training_arguments = TrainingArguments(
output_dir="./Reasoning_keyword2",
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_strategy="epoch",
logging_steps=100,
logging_strategy="steps",
learning_rate=1e-4,
fp16=False,
bf16=False,
group_by_length=True,
disable_tqdm=False,
report_to="none",
)
trainer = SFTTrainer(
model=model,
train_dataset=dataset_train,
max_seq_length= 1024, # 2048
tokenizer=tokenizer,
args=training_arguments,
formatting_func=formatting_prompts_func,
packing= False,
)
trainer.train()
QEU:FOUNDER : “ここまでで、与えられたデータセットでのSFT学習ができます。驚くことに、Unslothを使うとリソースが、とっても少なくなるんだわ・・・。”


D先生: “おっと、GPUメモリがたった8GB程度でも学習できるんだ・・・。前回、P3でfinetuneのトライアルをやったときには、すごい量のメモリが必要でした。”


QEU:FOUNDER : “おなじfinetuneでも、採用しているテクノロジが違うので一概には比較できない。もっとも大きな違いは、このUnslothのL3モデルが量子(4bit)化されて、小さくなっていることだろうね。さてと・・・、ここから学習されたモデルで推論のテストをやってみましょう。”


D先生: “さすがの実力ですね。はっきりいって、J→Eは必要になるのかな?J-Jでもいいんじゃない?”
QEU:FOUNDER : “じゃあ、非常に簡単な質問で試してみましょう。”


D先生: “少しだけ「実力不足」かな?それでも、P2モデルよりも圧倒的に進歩しています。”
QEU:FOUNDER : “次は翻訳の実力を試してみましょう。”
(J to E)


(E to J)


D先生: “J語の翻訳は、ほぼ完璧ですね。念のためにC語の場合も使ってみたいですね。”
(C to E)


(C to J)


QEU:FOUNDER : “L3-8bレベルでは、ぜんぜん外国語の処理は無理かなと思っていたら、なかなかに・・・。どうしてどうして・・・。”
D先生 : “すごいですね。P3って、L3よりもパフォーマンスがいいんでしょ?”
QEU:FOUNDER : “L3-8bがP3-miniレベルだから、P3-smallならばGPT-3.5以上になるんじゃない?そうなれば、さらにやれることも増えていきます。ただし、現在のところP3用のUnslothは開発中らしいです。さてと宣伝です。是非、カンパ(↓)をお願いします。”
>寄付のお願い(click here for buy me a cup of coffee)<
D先生: “皆さま、いっぱいの温かい「Buy me a cup of coffee」をいただけませんでしょうか。”
~ まとめ ~
・・・ 前回のつづきです ・・・
QEU:FOUNDER : “「マズローの5段階=出世競争」と考えてきた、「条件付けまみれ」で育った、昭和文化の産物(ヒト)だよね。令和(以降)じゃ、こんな考え方は通用しないよ。”


C部長 : “多様な社会が実現するための準備ができつつあるということですね。それにしても、この概念図は難しすぎるかなあ・・・?”
QEU:FOUNDER : “じゃあ聞くけど・・・。C先生は、このモデル図(↓)は理解できるの?”


C部長 : “昭和の理論のひとつである、タグチメソッドのQEU的な解釈ですね。汎用技術構造では、横軸がメトリックスの生成過程を示し、縦軸が直交表による最適解を表現しています。で?それがなにか?”


QEU:FOUNDER : “両者は同じメカニズムだよ!つまり、コレ(↑)!!”
C部長 : “ピンク・なんちゃら・・・?それにしても、こんなに変な形のプリズムを初めてみました。”
QEU:FOUNDER : “汎用技術構造って、「プリズムで遊ぼう!」なんです。まず、汎用技術構造の横軸の学習段階で、カスタマイズされたプリズムを作ります。それも、すっごく複雑なやつ・・・。そして、次に縦軸の要領で、そのプリズムに光を当て、そこから出てくる光の形を出力します。これが「推論」というやつです。昭和のタグチメソッドでは、直交表がその光の役割を果たしたわけです。”
C部長 : “要するに、昭和の手法では計算力が手に入らなかったので、プリズムと光を極限に簡単化したSN比と直交表を使わざるを得なかった。でも、いまのように強力な計算力(GPU)が手に入る場合には、コンピューター上にプリズムを育てて、そこに光を当てることで、より高度のことができると・・・。”


QEU:FOUNDER : “QEUシステムのLLMアプローチにおいて、プリズムに相当するのは「モデル」であり、光とは「PROMPT ENGINEERING」になるんです。以前に話をしたように、外観自動検査機についても、同じく汎用技術構造の応用です。”
C部長 : “こう考えてみると、「プロンプト・エンジニアリングの開発」って侮れないですね。”
QEU:FOUNDER : “いまのところ、我々は、単純な文章出力のためにプロンプト・エンジニアリングを使っています。本当は、もっと違う使い方ができるんじゃないかと常に考えています。”
C部長 : “どのみち、LLMモデルを使いこなさないといけないですから、ウォームアップ練習としてfinetuneとRAGを使ったアプリケーション開発をするのは無駄ではないです。”
(モノの価値とは)
- (生活が、仕事が)便利になる
- 自分を変えることができる
- モノがあると快適、楽しい
- 条件付け→パーソナリゼーション
自分の社会の中での位置づけ
QEU:FOUNDER : “少なくとも、このモノ(プロジェクト)は「めちゃくちゃ面白い」よ。いままでにないことができるんじゃないかな。”



コメント
コメントを投稿